Published
- 6 min read
Cómo OpenAI escala PostgreSQL para servir a 800 millones de usuarios de ChatGPT
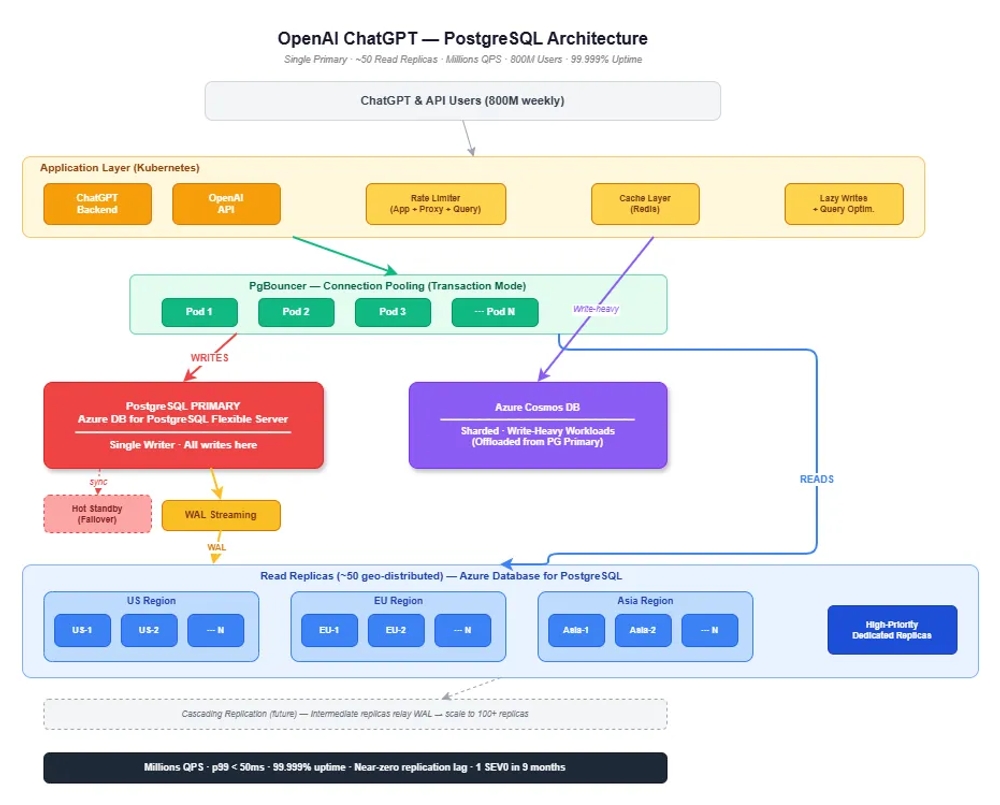
Cuando pensamos en la base de datos detrás de uno de los productos de IA más usados del planeta, muchos imaginarían un cluster distribuido de última generación. La realidad es más sorprendente: ChatGPT corre sobre una sola instancia primaria de PostgreSQL, sin sharding, desplegada en Azure. Y funciona.
OpenAI publicó recientemente los detalles de cómo escalaron PostgreSQL para manejar millones de queries por segundo, manteniendo una latencia p99 de milisegundos bajos y una disponibilidad del 99.999%. En este post desgloso su arquitectura pieza por pieza.
La arquitectura general
El diseño sigue un patrón clásico de primary-replica, pero llevado al extremo:
- Un solo Primary (escritor) en Azure Database for PostgreSQL Flexible Server.
- ~50 read replicas distribuidas geográficamente (US, EU, Asia).
- PgBouncer como connection pooler en modo transacción.
- Azure Cosmos DB para descargar workloads de escritura intensiva.
- Caching layer (Redis) que absorbe la mayoría del tráfico de lectura.
El flujo es simple: las peticiones llegan a la capa de aplicación en Kubernetes, pasan por PgBouncer, y se bifurcan — las escrituras van al Primary, las lecturas se reparten entre las réplicas.

Por qué un solo Primary y no sharding
Parece contraintuitivo, pero OpenAI tomó esta decisión por razones pragmáticas. Fragmentar (shard) PostgreSQL habría requerido modificar cientos de endpoints de la aplicación, un esfuerzo de meses o años. Como el workload de ChatGPT es mayoritariamente de lectura, la estrategia más eficiente fue mantener un solo escritor y escalar las lecturas horizontalmente con réplicas.
El sharding sigue siendo una opción futura, pero no una necesidad inmediata.
PgBouncer: el multiplicador de conexiones
Este es uno de los componentes más críticos. PostgreSQL crea un proceso del sistema operativo por cada conexión, consumiendo entre 5 y 10 MB de memoria cada una. Con miles de pods de Kubernetes intentando conectarse simultáneamente, la base de datos se saturaría en segundos.
PgBouncer se coloca entre la aplicación y PostgreSQL como un proxy que mantiene un pool de conexiones pre-abiertas. Cuando un pod necesita hacer una query, PgBouncer le presta una conexión existente; cuando termina la transacción, la devuelve al pool.
OpenAI lo ejecuta en modo transacción: la conexión solo se ocupa durante el BEGIN...COMMIT, no durante toda la sesión. Esto es clave porque una petición típica de ChatGPT pasa segundos procesando en el modelo de IA y solo milisegundos hablando con la base de datos. El resultado: la latencia de conexión bajó de ~50ms a ~5ms.
Además, PgBouncer actúa como amortiguador ante picos repentinos. Si la caché falla y miles de peticiones llegan a la DB de golpe (un “cache-miss storm”), PgBouncer las encola en vez de dejar que PostgreSQL reciba el impacto directo.
WAL Streaming y réplicas geo-distribuidas
El Primary genera un Write-Ahead Log (WAL) — un registro secuencial de todas las operaciones de escritura — y lo transmite en streaming a las ~50 réplicas. Cada réplica aplica esos cambios para mantenerse sincronizada, con un lag de replicación cercano a cero.
Las réplicas están distribuidas por regiones geográficas, co-localizadas con los proxies y clientes de aplicación para minimizar la latencia de red. OpenAI además separa las réplicas en dos categorías:
- Réplicas de alta prioridad: dedicadas exclusivamente a peticiones críticas, aisladas del tráfico general.
- Réplicas de baja prioridad: manejan consultas menos urgentes, backfills y tareas internas.
Esta separación evita el efecto “noisy neighbor”, donde una consulta pesada en una réplica degrada el servicio para todos.
Reducir la presión de escritura
Aquí está el verdadero desafío. PostgreSQL usa MVCC (Multi-Version Concurrency Control): cada UPDATE crea una nueva versión completa de la fila. Esto genera “write amplification” — más I/O, más bloat en tablas e índices, y más trabajo para el autovacuum.
OpenAI atacó esto desde múltiples frentes:
- Offloading a Cosmos DB: los workloads de escritura que pueden fragmentarse se migraron a Azure Cosmos DB, un sistema distribuido. PostgreSQL se reserva para datos relacionales que requieren consistencia fuerte.
- Lazy writes: las escrituras no urgentes se retrasan y agrupan para suavizar picos.
- Rate limiting en múltiples capas: a nivel de aplicación, proxy y query individual, para prevenir tormentas de escritura.
- Disciplina operacional estricta: no se permite crear tablas nuevas en el cluster principal, los backfills tienen rate limits tan agresivos que pueden tardar más de una semana, y cualquier cambio de esquema que requiera reescribir la tabla completa está prohibido.
Protección contra fallos en cascada
OpenAI identificó patrones recurrentes de incidentes:
Cache-miss storms: cuando la capa de caché (Redis) falla, miles de peticiones que normalmente no tocan la DB se redirigen de golpe a PostgreSQL. La solución fue implementar cache locking — solo una petición regenera la caché, el resto espera.
Queries asesinas de ORMs: los ORMs generan joins de múltiples tablas (hasta 12 en algunos casos) que saturan la CPU. OpenAI movió parte de esa lógica de unión a la capa de aplicación.
Retry storms: cuando un servicio falla, los clientes reintentan simultáneamente, multiplicando la carga. Se implementó exponential backoff y circuit breakers.
Transacciones idle: queries que se quedan bloqueadas por más de 1 segundo se terminan automáticamente con idle_in_transaction_session_timeout, evitando que bloqueen cambios de esquema y el autovacuum.
Hot Standby: el seguro contra catástrofes
Con un solo Primary, si este cae, todo cae. OpenAI mantiene un Hot Standby — una copia sincronizada del Primary que recibe todos los cambios en tiempo real. Si el Primary falla, el Hot Standby toma el control inmediatamente, minimizando el downtime.
El futuro: Cascading Replication
A medida que crece el número de réplicas, el Primary tiene que enviar el WAL a cada una, sumando overhead de CPU y red. OpenAI está experimentando con cascading replication: réplicas intermedias que reciben el WAL del Primary y lo retransmiten a réplicas “downstream”.
Esto forma una estructura en árbol que permitiría escalar a más de 100 réplicas sin sobrecargar al Primary. Sin embargo, añade complejidad operacional, especialmente en escenarios de failover, por lo que todavía está en fase de pruebas.
Los números
Los resultados hablan por sí mismos:
- Millones de queries por segundo combinando lecturas y escrituras.
- Latencia p99 < 50ms para el 99% de las peticiones.
- 99.999% de disponibilidad (five nines).
- Lag de replicación cercano a cero.
- Solo 1 incidente SEV0 relacionado con PostgreSQL en 9 meses, causado por un pico viral de tráfico durante el lanzamiento de ChatGPT ImageGen.